엣지에서의 추론

엣지에서 손쉽게 ML 모델을 배포
전 세계적으로 빠르고 안전하며 확장 가능한 추론을 달성해 보세요.
엣지 추론을 통한 AI 애플리케이션 혁신
Gcore는 사용자와 더 가까운 곳에서 추론을 수행하여 지연 시간을 줄이고 초고속 응답을 지원하며 실시간 AI 지원 앱을 활성화합니다.
필요한 곳에 자동으로 배포되는 단일 엔드포인트를 사용하고 Gcore가 강력한 기본 인프라를 관리해 탁월한 성능을 발휘할 수 있습니다.
엣지에서 Gcore 추론이 필요한 이유는 무엇일까요?
고성능
높은 처리량과 초저지연으로 전 세계에 빠른 AI 애플리케이션을 제공하세요.
확장성
전 세계에 최첨단 AI 애플리케이션을 손쉽게 배포하고 확장할 수 있습니다.
비용 효율성
수요에 따라 리소스를 자동으로 조정하여 사용한 만큼만 비용을 지불할 수 있습니다.
빠른 출시 기간
인프라 관리 없이 AI 개발을 가속화하여 엔지니어링 시간을 절약할 수 있습니다.
사용 편의성
직관적인 개발자 워크플로를 사용하여 신속하고 간소화된 개발 및 배포를 진행해 보세요.
엔터프라이즈 지원
통합 보안 및 로컬 데이터 처리의 이점을 활용하여 데이터 프라이버시와 주권을 보장할 수 있습니다.

지금 체험해 보기
플레이그라운드를 통해 엣지에서의 지코어 추론을 직접 체험해 보세요.
SDXL-Lightning
이미지 생성기Mistral-7B
LLM / ChatWhisper-Large
ASR
이미지 생성하기
Playground에 포함된 AI 모델에는 개발자 문서에 설명된 대로 타사 라이선스 및 제한 사항이 적용될 수 있습니다.
Gcore는 이러한 모델에서 생성된 출력의 정확성이나 신뢰성을 보장하지 않습니다. 모든 출력물은 "있는 그대로" 제공되며, 사용자는 이러한 모델의 사용으로 인해 발생하는 결과에 대해 지코어가 어떠한 책임도 지지 않는다는 데 동의해야 합니다. 모델 생성 결과물을 사용할 때 해당 타사 라이선스 약관을 준수하는 것은 사용자의 책임입니다.
엣지에서의 추론 경험해 보기
지금 바로 엣지에서의 추론 잠재력을 활용해 사용자에게 더욱 강력한 AI 기능을 제공해 보세요.
엣지에서의 추론
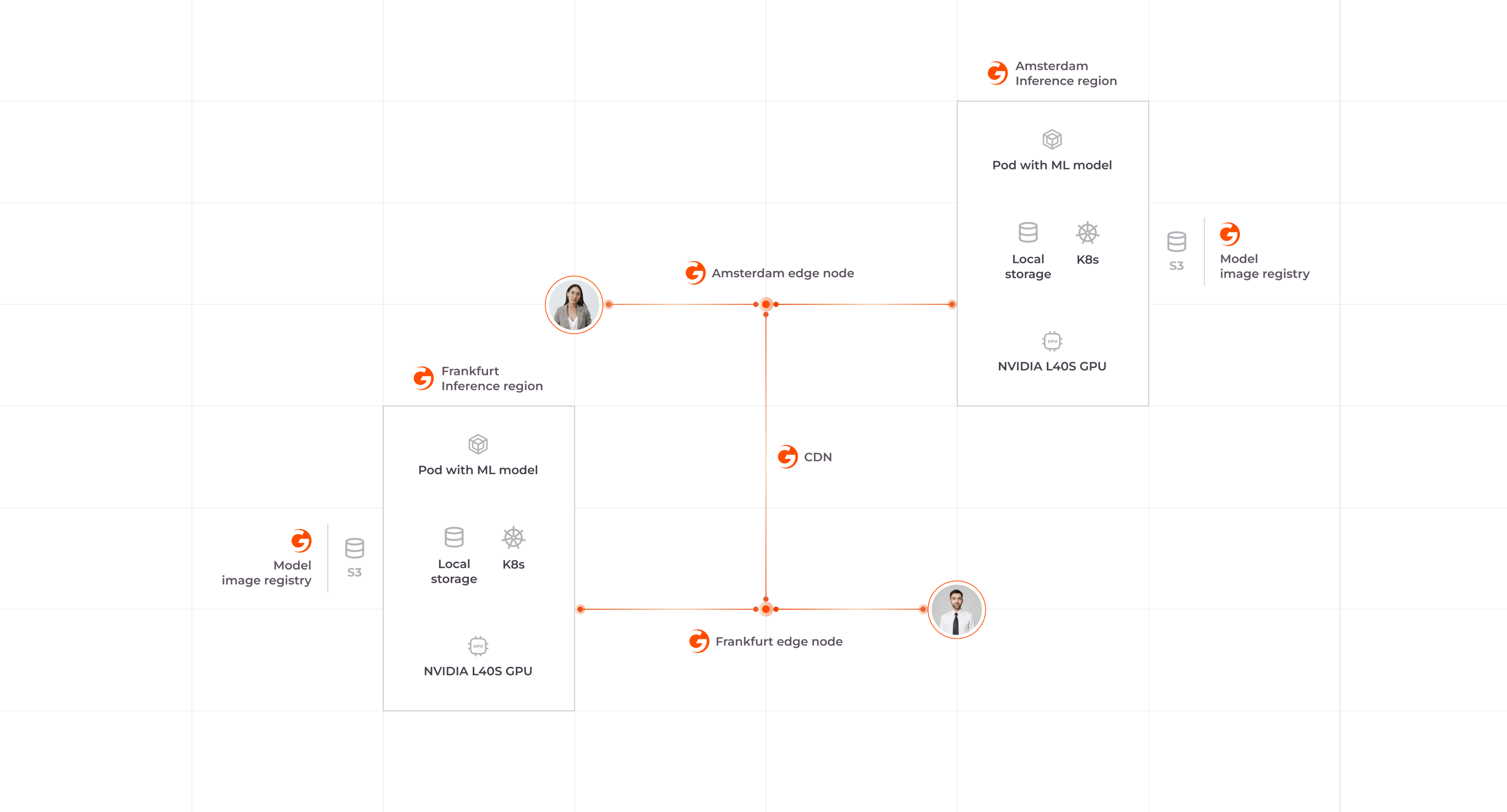
작동 방식
AI 앱의 잠재력을 최대한 활용해 보세요.

저지연 글로벌 네트워크
전략적으로 배치된 180개 이상의 엣지 PoP와 평균 30ms의 네트워크 레이턴시로 모델 응답 시간을 가속화하세요.
강력한 GPU 인프라
전용 인스턴스 또는 서버리스 엔드포인트로 제공되는 AI 추론용으로 설계된 NVIDIA L40S GPU로 모델 성능을 향상시켜 보세요.
유연한 모델 배포
주요 오픈 소스 모델을 실행하거나, 기본 독점 모델을 미세하게 조정하거나, 자체 사용자 지정 모델을 배포해 보세요.
모델 자동 스케일링
사용자 요청과 GPU 사용률에 따라 동적으로 확장하여 성능과 비용을 최적화합니다. HTTP 요청을 사용하여 AI 추론 워크로드를 효율적으로 관리하세요.
글로벌 추론을 위한 단일 엔드포인트
손쉽게 모델을 애플리케이션에 통합하고 인프라 관리를 자동화하세요.
보안 및 규정 준수
통합 DDoS 보호 및 GDPR, PCI DSS, ISO/IEC 27001 표준 준수의 이점을 누려보세요.
다양한 사용 사례를 위한 유연한 솔루션
기술
- 제너레이티브 AI 애플리케이션
- 챗봇 및 가상 비서
- 소프트웨어 엔지니어를 위한 AI 도구
- 데이터 증강
게임
- AI 콘텐츠 및 지도 생성
- 실시간 AI 봇 커스터마이징 및 대화
- 실시간 플레이어 분석
미디어 및 엔터테인먼트
- 콘텐츠 분석
- 자동 전사
- 실시간 번역
리테일
- 셀프 체크아웃 및 머천다이징이 가능한 스마트 식료품점
- 콘텐츠 생성, 예측 및 추천
- 가상 체험판
자동차
- 자율 주행 차량을 위한 신속한 대응
- 첨단 운전자 지원
- 차량 개인화
- 실시간 교통 업데이트
제조
- 생산 파이프라인의 실시간 결함 감지
- 신속한 응답 피드백
- VR/VX 애플리케이션
자주 묻는
질문
AI 추론은 학습된 ML 모델이 새로운 데이터를 기반으로 전에 없던 예측 및 의사 결정을 내리는 것을 의미합니다. 추론은 새로운 채팅 프롬프트와 같은 실제 문제에 ML 모델을 적용하여 유용한 인사이트나 조치를 제공합니다. AI 추론과 작동 방식에 대해 자세히 알아보려면 블로그 게시물을 참조하세요.
엣지에서의 AI 추론과 클라우드 기반 AI 추론은 데이터 처리가 이루어지는 위치가 다릅니다. 엣지 AI 추론은 로컬 디바이스 또는 그 근처에서 ML 모델을 실행하여 클라우드 AI 추론의 경우처럼 원격 서버로 데이터를 전송할 필요 없이 실시간 데이터 분석 및 의사 결정을 내릴 수 있습니다.
엣지에 AI 추론을 배포하면 클라우드의 AI 추론에 비해 지연 시간이 단축되고 보안이 향상되며 네트워크 연결에 대한 의존도가 감소합니다. 엣지에서의 추론은 제너레이티브 AI 및 객체 감지와 같이 실시간 처리와 초저지연이 필요한 AI 앱에 특히 유용합니다.
네 AIoT 디바이스는 엣지에 배포된 ML 모델에 의존합니다. 엣지에서의 Gcore Inference는 AIoT 시스템에 필수적인 저지연 시간, 높은 처리량, 데이터 소스에 대한 근접성을 제공합니다.
Gcore는 엣지에서의 추론과 함께 사용할 수 있는 AIoT를 포함한 IoT 전용 솔루션인 5G 네트워크를 제공합니다. 5G 네트워크는 5G를 통해 원격 AIoT 디바이스를 안전하고 안정적이며 빠르게 연결할 수 있는 방법입니다. 5G 네트워크 기능에 대해 자세히 알아보려면 5G 네트워크 문서를 참조하세요.
NVIDIA L40S는 AI 추론을 위해 특별히 설계된 최신 범용 데이터센터 GPU입니다. A100 및 H100과 같은 다른 강력한 NVIDIA GPU에 비해 최대 5배 빠른 추론 성능을 제공하며 가격 대비 성능이 뛰어납니다. 블로그 게시물에서 L40S에 대해 자세히 알아보기와 다른 인기 NVIDIA GPU와의 차이점을 알아보세요.
귀사의 프로젝트 논의를 위해 지코어에 문의하세요
엣지에서의 추론이 귀사의 AI 애플리케이션을 어떻게 향상시킬 수 있는지 자세히 알아보세요.
지코어의 다른 제품 체험 해보기
GPU Cloud
AI 트레이닝 및 고성능 컴퓨팅을 위한 A100 및 H100 NVIDIA GPU가 탑재된 가상 머신 및 베어 메탈
서비스형 컨테이너(Container as a Service)
클라우드에서 컨테이너화된 애플리케이션과 ML 모델을 실행하기 위한 서버리스 솔루션
관리형 쿠버네티스
AI/ML 워크로드를 위한 GPU 워커 노드 지원이 포함된 완전 관리형 쿠버네티스 클러스터
패스트엣지(FastEdge)
서버리스 애플리케이션 배포를 위한 저지연 엣지 컴퓨팅
오브젝트 스토리지
데이터 저장 및 검색을 위한 확장 가능한 S3 호환 클라우드 스토리지
서비스로서의 기능(Function as a Service)
기성 환경에서 코드를 실행하기 위한 서버리스 컴퓨팅 서비스