


























大規模AIモデルトレーニングは膨大なデータセットを解釈して学習する能力を持つ高度なAIモデルの構築を目的としたプロセスに含まれるステップの1つです。 大規模AIモデルは従来の機械学習を超える能力を持っており、広範かつ複雑なデータ構造からインサイトを抽出し、テクノロジー主導の分野に変革をもたらすソリューションの基礎を築きます。 トレーニングとはモデルが意思決定や予測を行うためにデータから学習を行うことを指し、トレーニングプロセスは膨大なデータセットに合わせて最適化する必要があります。 この記事では戦略的な意思決定を行うための大規模AIトレーニングの重要性を考察し、その仕組みを説明し、そのような強力な計算ツールの開発に関連する課題とベストプラクティスの概要を取り上げます。
大規模AIモデルトレーニングとは?
大規模AIモデルトレーニングとは、大量のデータに基づいて人工知能(AI)モデルを開発するプロセスを指します。 このプロセスには常に数兆のデータ、数十億のパラメーターを持つ複雑なアーキテクチャ、および強力な計算リソースを使用する巨大なモデルのトレーニングが伴いますが、一般的に認められている「大規模」と称すべきモデルの大きさは定義されていません。
とはいえ、OpenAIのGPTモデルは「大規模」モデルと称される有名な例として機能しています。 2018年の時点で1億1,700万のパラメーターと約6,000億のトークンを使用するGPT-1は大規模だと考えられていました。 2023年まで話を進めると、GPT-4は規模が劇的に拡大しており、単語、画像、およびコードを含む約1.7兆のパラメーターと約13兆のトークンを使用するようになりました。 大規模モデルの領域に入るのに必要なデータセットのサイズが年々増しているのは明らかです。
大規模AIモデルトレーニングと通常のものとの違い
大規模AIモデルのトレーニングプロセスはすべてのAIモデルと同様で、さまざまなタスクに秀でた汎用的なモデルを作成するという主な目標を目指しているという点ではどちらも同じです。 このようなタスクはあらゆる規模のAIモデルに共通のもので、自然言語処理やコンピュータービジョンなどがあります。 主な違いは、使用されているテクノロジーにあります。 モデルの規模と複雑度が増すにつれて、より特殊なテクノロジーが必要になっています。
車との共通点について考えてみましょう。 時速100 mphに到達できる車を製造するのは ごく一般的なことです。 一部のメーカーは150~200 mphまで速度を上げることができています。 しかし、特殊なテクノロジーを搭載した独自モデル向けに300 mphのような速度を実現するとなると話は変わっています。 これは通常のAIモデルから大規模AIモデルへの進行にも当てはまります。モデルが大規模化するにつれて、増加するデータの量と複雑さの要件に対応するためのトレーニングに必要なテクノロジーもより高度かつ特殊なものになります。 大規模AIモデルトレーニングの仕組みについて、必要とされるハードウェアとソフトウェアなどのテクノロジーと必要とされる理由を含めて考察しましょう。
大規模AIモデルトレーニングの仕組み
人工知能は問題を概念的に理解することから始まり、最終的にその問題を解決できるモデルを開発するまでの構造化されたプロセスで構成されています。 上の画像で可視化されているプロセスの詳細は、Gcore のAI入門ガイドに記載されています。
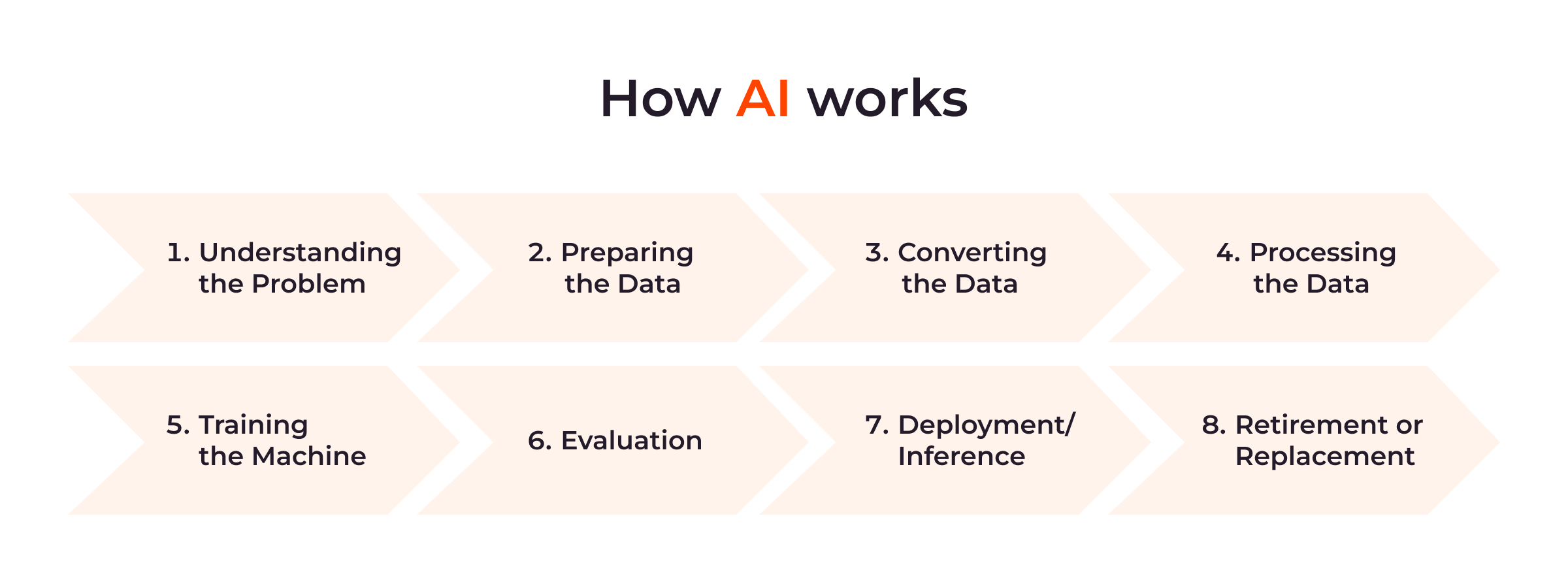
トレーニングの第5ステップでは、モデルが意思決定や予測を行うためにデータから学習します。 大規模AIモデルの場合、このトレーニングステップは通常のプロセスとは異なっています。なぜなら、モデルが広く深く学習できるようにするため、高度なアルゴリズムと大量の計算リソースを要求する莫大な量のデータが必要になるためです。 一般的には分散コンピューティングと並列処理が導入されます。 そのため、通常のモデルと比較して多様なハードウェアとソフトウェアが必要になり、事前トレーニングと微調整の段階の両方を変更する必要も生じます。 このような変更について詳細に見てみましょう。
分散コンピューティングと並列処理
分散コンピューティングと並列処理はトレーニング時間の短縮と大規模AIモデルに関わる広範なデータの処理に対応するための重要な戦略であり、どちらも特殊なハードウェアとソフトウェアを必要とします。 分散コンピューティングと並列処理の主な違いは、その範囲と実装にあります。
並列処理はあるデータセットに対して複数のタスクを同時実行することでデータの処理を高速化するものです。 並列処理には以下が含まれます。
- データ並列処理: 複数のデータセットが同時に処理されます。
- モデル並列処理: 複数の異なるモデル構成要素が別々のマシンで処理されるものです。単一のホストでリソースをスケールアップするのは不可能であるため、大規模モデルトレーニングでは必須となることもしばしばです。
- パイプライン並列処理: 複数の異なるモデルの段階が複数のプロセッサに分散され、同時処理されるものです。
並列処理は単一マシンでも複数マシンでも行われる可能性があります。
これに対し、分散コンピューティングとは相互にネットワーク接続された複数のコンピューターやクラスターなど、複数のマシンを使用して大量のデータを処理・分析することを指します。 これはトレーニングハードウェアの全体的な能力を強化し、単一マシンの処理能力を超える大規模なデータセットに対応できるようにする水平スケーリングの一種です。
各マシンがモデルの一部またはデータのサブセットをトレーニングするため、単一マシンよりも高速にタスクを完了できます。 各マシンの結果は集約され、最終的な結果が生成されます。
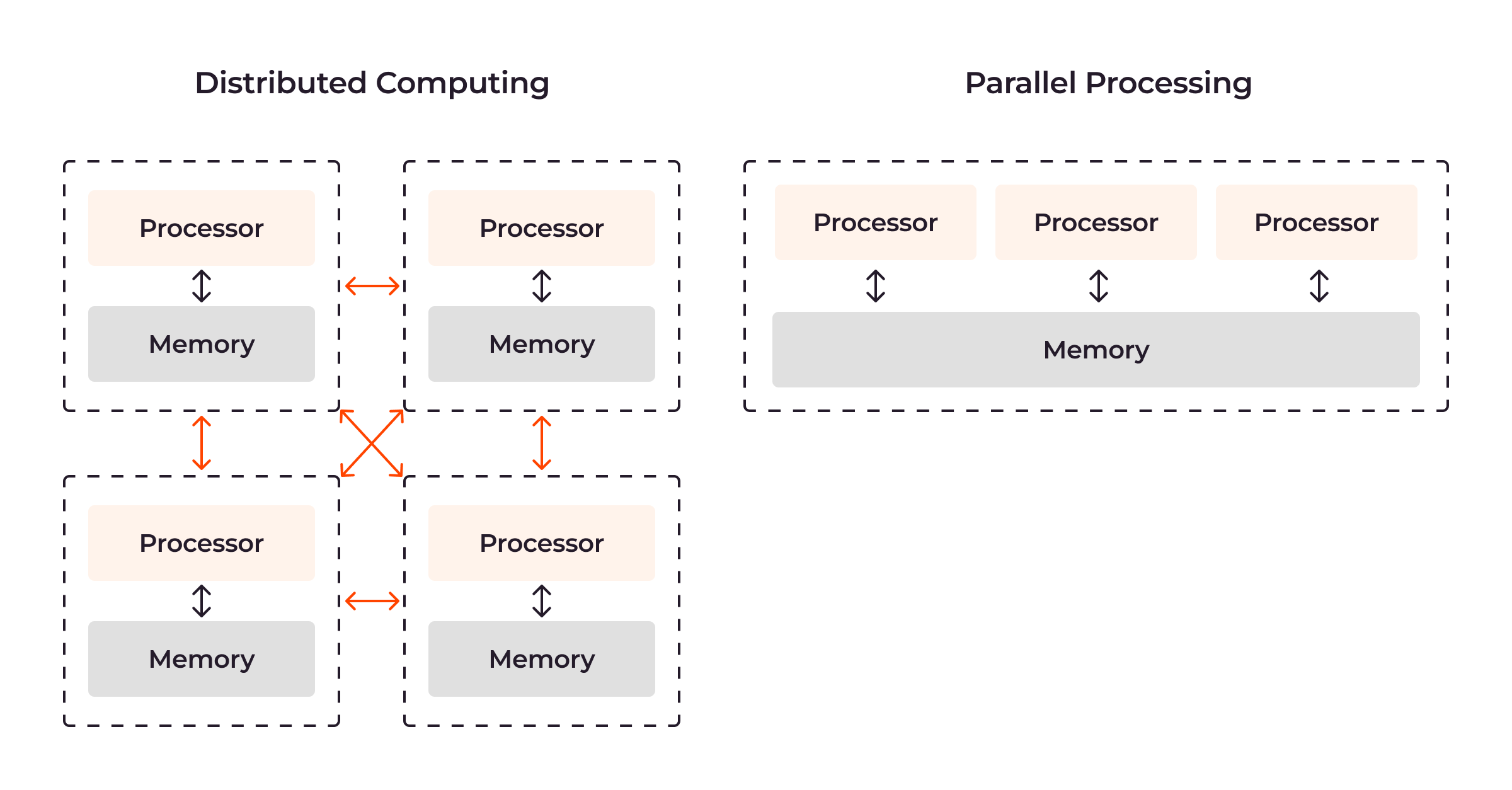
大規模AIモデルトレーニングでは、分散コンピューティングと並列処理が連携することもしばしばです。 分散コンピューティングはトレーニング構造の外部レイヤーとして機能し、ハードウェアの能力を拡張して莫大なデータセットを処理します。 並列処理はその内部レイヤーとして機能し、この拡張された環境内での効率を向上させます。
これらの処理を補助するには、特殊なハードウェアとソフトウェアが必要になります。
ハードウェア
GPU(画像処理装置)はスループットが高く、大量のデータを同時に処理する能力を持ちます。 それが多くの処理を並列実行する場合に好んで選ばれるハードウェアとなり、 AIトレーニングが要求する繰り返しの多い複雑な 計算に適している理由です。 IPU (知能処理装置) は特定のAI計算向けの高効率な代替製品として台頭しているものであり、特殊なAIワークロードの最適化を実現するものです。 Gcoreの AIインフラストラクチャ(NVIDIA A100やH100 GPUなどを含む) は大規模なトレーニングに必要な能力を提供します。
分散コンピューティングではクラスター内で相互接続されたGPUやIPUが連携し、単一マシンでは不可能な大規模AIモデルの処理を実現しています。 並列処理の場合、すべてのGPUとIPUに複数のタスクを同時実行して並列処理をサポートするような多数のコアが搭載されています。
ソフトウェア
高効率な大規模AIトレーニングはこのような高度なハードウェアと特殊なソフトウェアフレームワークを組み合わせることで実現されています。 TensorFlowやPyTorchなどのこのようなフレームワークはGPUとTPU(テンソル処理装置)の能力を活用し、並列処理を最適化と効率的な大規模データセットの管理によってパフォーマンスを最大化するように設計されています。 また、分散コンピューティングを組み込みでサポートしており、効果的なスケジュール管理と負荷分散アルゴリズムによって効率的なタスク分散とプロセッサの利用を実現します。
AIサービスとしてのインフラストラクチャ(IaaS)はあらかじめソフトウェアとの統合がセットアップされた状態のハードウェアを提供することで、ソフトウェアの処理を単純化します。 たとえば、GcoreのGPUは多数の代表的なフレームワークやTensorFlow、PyTorch、Keras、PaddlePaddle、およびHugging Faceのようなツールが搭載されています。
大規模AIモデルトレーニングのステップとベストプラクティス
大規模AIモデルのトレーニングは通常のAIモデルトレーニングと同様、通常は2段階の手法で行います。 まずは幅広い知識を得るため、LLM向けのインターネットテキストコーパスのような広範かつ関連性の高いデータセットを使用してモデルが一般的なタスクで事前トレーニングされます。 その後、モデルは特殊なユースケースに対応するより小さなタスク固有のデータセットに基づいて微調整されます。 たとえば、サポートチャットボットをトレーニングする目的でカスタマーサービスの対話に基づいてモデルを微調整できます。
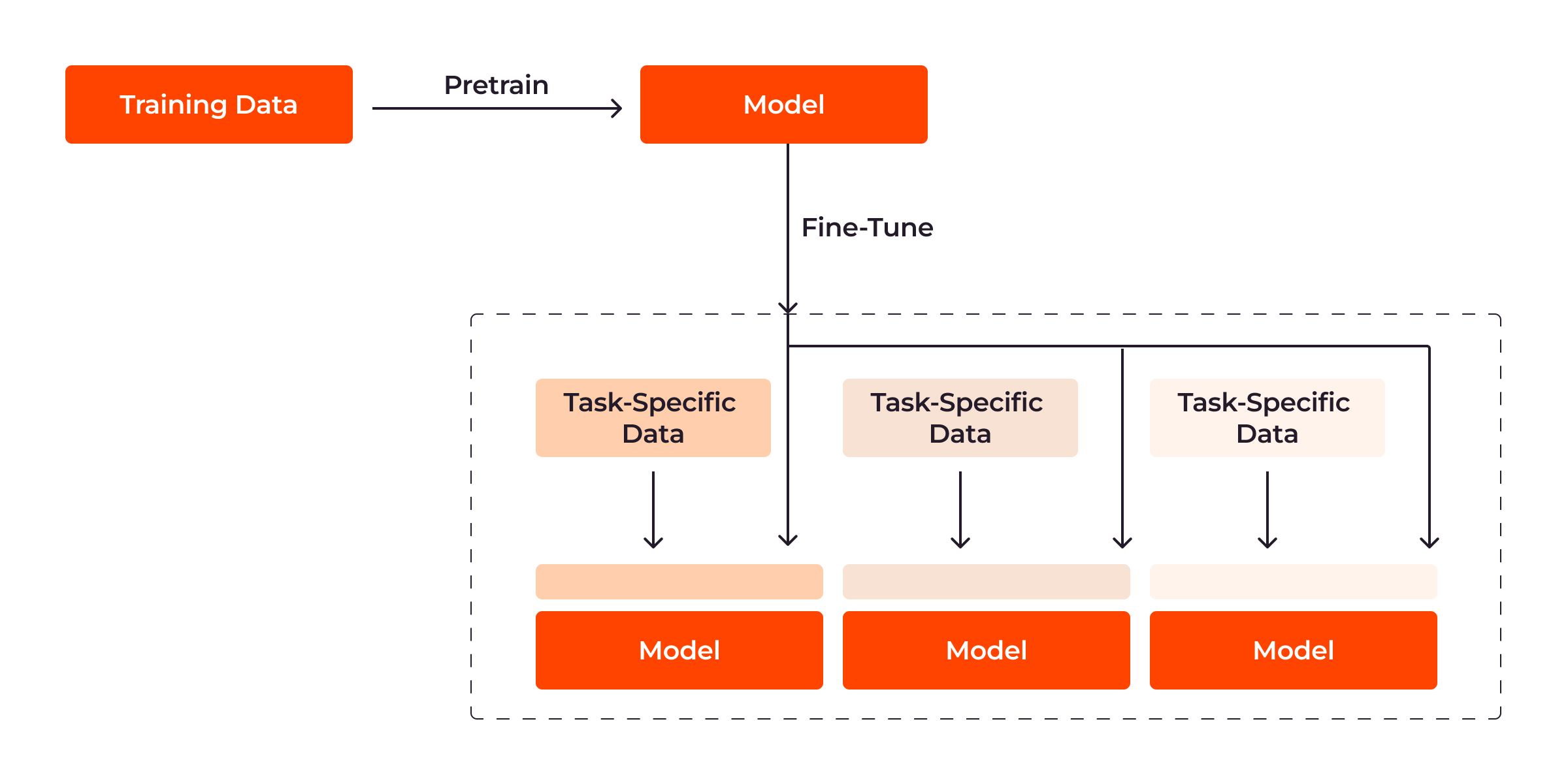
各段階には、トレーニングのプロセスと結果を最適化するために従うべき大規模AIモデルに固有の決まったベストプラクティスがあります。
事前トレーニング
事前トレーニングの段階では、モデルは幅広いデータに触れることで全体的な特徴とパターンを学習できるようになります。 この初期データセットの品質が、モデルの能力の基礎を築く決め手となります。
事前トレーニングのベストプラクティスには以下があります。
- モデルが問題空間を包括的に理解できるよう、正確にラベル付けされた多様なデータセットを使用する。 これにより、以下を実現できます。
- より小規模なデータセットの組み合わせを使用し、より大規模で複雑なデータセットを作成する。
- 新しいデータセットのデータセットにボランティアを参加させてクラウドラベル付けを使用する。 クラウドラベル付けはMozilla Common Voice向けに使用されていました。 この手法により、多様性が向上してバイアスが軽減されます。
- より具体的な既存の複数のAIモデルを使用し、データ解析と新しいデータセットの構築を行う。
- 詳細なパフォーマンスログを記録し、モデルの学習進捗を追跡してすべてのエラーを早期に発見する。 これは通常規模のデータセットにも当てはまることですが、大規模なデータセットでは特に重要です。完全なトレーニングプロセスが要求するリソースがあり、エラーが早期に特定されない場合に無駄が発生する可能性があるためです。
- この段階の広範な計算ニーズを対処してすべてのデータを効率的に読み込むため、堅牢で特殊なハードウェアと技術を使用する。
- 混合精度トレーニングを組み込んでメモリ使用量を減らし、モデルの品質を損なうことなく既存ハードウェアでより高速なトレーニングを可能にする。
- モデル微調整用のエラー検知ガイドとなる勾配を複数の小さなバッチに格納し、モデルパラメーターの更新頻度を下げる勾配累積を使用し、GPUメモリの使用を効率的に管理する。
微調整
微調整の段階では、事前トレーニングされたモデルが実行する必要のある特定のタスクに関するより具体的なデータセットに基づいてさらにトレーニングされます。 ここでモデルの一般的な知識が特殊なアプリケーションに合わせて磨き上げられます。
たとえば医療モデルの場合、事前トレーニングでは幅広い胸部CTスキャン画像を使用し、ここでは肺がんの症例を示すCT画像を使用してトレーニングされるかもしれません。 肺炎を示すCTを微調整することで、同じ事前トレーニングセットから異なる医療モデルを作成できる可能性があります。
微調整のベストプラクティスには以下があります。
- 具体的なタスクに密接に関わるより小規模なデータセットを選択し、モデルのその能力を改良できるようにする。
- メトリクスを監視してハイパーパラメーターを調整し、モデルが想定するアプリケーションに合わせてパフォーマンスを最適化する。 これはすべてのAIモデルトレーニングに当てはまることですが、大規模データセット向けの利用リソースを管理するうえでは特に重要です。 大規模データセットのパフォーマンスが10%無駄になると、全体のトレーニング時間が数日または数週間も増える可能性があります。 ハイエンドなMLハードウェアの価格を考慮すると、これはプロジェクトにかなりの金銭的影響を及ぼす可能性があります。
- 非常に大規模なモデルやデータセットを処理する場合などは、分散学習の手法を採用してワークロードを効率よく管理する。
- ニューラルネットワークで不要なつながりを削除するために使用されるプルーニングやモデルのパラメーターの精度を下げるために適用される量子化などの手法を適用し、モデルの規模と計算需要を削減してモデルを展開できる状態にする。
大規模AIモデルトレーニングが重要な理由
大規模AIモデルトレーニングにより、モデルが大量のデータセットを解読して使用できるようになります。 これによってさらに高精度な予測、詳細なインサイト、高速な処理が可能になるほか、複雑な変数量の多いシナリオに対応できるようになるため、標準的なAIモデルのトレーニングよりも意思決定、運用パフォーマンス、複数業界にわたる競争戦略を強化できます。 まずは大規模データセットがこのようなメリットを具体的にどのように実現しているかを理解しましょう。
大規模AIモデルが詳細なインサイトを提供する仕組み
AIを大量のデータセットに基づいてトレーニングすると、より高い精度でパターンと相関関係を識別できるようになります。その結果、小規模なデータセットを使用する場合よりも正確で有益な予測を得ることができます。 規模が大きくなるにつれて、より詳細かつ包括的なインサイトを引き出せるようになります。
たとえば、eコマースでは比較的小規模なモデルでは見逃される可能性のある顧客行動の細かな傾向を把握し、それに沿った対応を取ることができます。 小規模なAIモデルでは、最も購入されている商品、アクセス頻度の高いページ、および顧客レビューのような基本的なデータを分析できる可能性があります。 しかし、比較的大量のデータセットに基づいてトレーニングされた大規模AIモデルなら、より細かな傾向を捕捉できる可能性があります。 ある特定の種類の製品を購入している顧客が決まった時刻に購入していることが分かるかもしれません。 比較的小規模なモデルでは容易に見逃される可能性のあるこのようなインサイトは、マーケティング戦略の最適化、顧客エクスペリエンスの個別化、販売促進、顧客維持率の向上に活用できます。
大規模なAIモデルは複雑な変数量の多いシナリオへの対応が得意で、多数の要素を同時に考慮して堅牢かつ包括的な予測を提供するため、気候モデリングや金融リスクの評価といった分野では特に役立ちます。 小規模なAIモデルでは患者の病歴、現在の症状、基本的な検査結果を解析し、具体的な疾病の可能性を予測できる可能性があります。 しかし、大規模なAIモデルなら、遺伝情報、環境要因、生活習慣、および睡眠パターンや身体活動を追跡するウェアラブルデバイスのデータを含む幅広いソースのデータを統合できる可能性があります。 特定の遺伝子マーカーを持つ患者が一定の生活習慣と環境暴露の組み合わせにより、ある特定の健康状態になるリスクが高いことを発見できるかもしれません。 このような詳細な理解により、大量の変数を把握し、それらを解釈して疾病の予測、予防戦略、個別化された治療計画を強化できるため、最終的には患者の転帰が改善されます。
これで大規模AIモデルトレーニングがもたらすメリットを理解できましたので、大規模AIモデルトレーニングを採用することでメリットを受ける5つの代表的な業界を見てみましょう。
医療
医療分野では、大規模AIモデルトレーニングによってROIとパフォーマンスが大幅に向上しています。 AIモデルは大量の患者データと医学研究成果を分析して病気の傾向を予測できるため、リソースの割り当てと予防医療の戦略改善につながります。 医療に関する大量かつ複雑な変数のデータが不足しており、結果的に実用的なインサイトが不足している可能性のある小規模なモデルに比べて、この手法は医療改善に役立つ実用的なインサイトを提供するだけでなく、より高い投資リターンを確実にもたらします。
AIの複雑な問題を解決する能力は、高度な病気診断と個別化された患者医療管理において明らかです。 たとえば、デューク大学では多数の病院と研究センターのデータを使用して大規模なAIモデルが開発され、個々の参加機関に自身のデータだけでは発見できないと思われる実用的なインサイトを提供しています。 このチームはこのデータセットに基づく特殊なAIモデルを数百、あるいは数千も作成する見込みです。
eコマース
Amazonやウォルマートのような巨大オンライン小売企業は大規模AIモデルを使用して消費者の行動と購入パターンを分析し、サプライチェーン管理の最適化と購入エクスペリエンスの個別化を行っています。 このような最適化は効率的な在庫管理につながり、リソースの無駄を減らしてよりスマートな支出を促します。 小売における大規模AIモデルは製品需要や消費者動向を予測し、企業が費用対効果と競争的優位性を維持するのにも役立っています。
テクノロジーと地図
Googleマップのような地図・ナビゲーションサービスは大量のデータを処理する大規模AIを活用して正確なルートの提案、交通予測、およびタイムリーな更新を行い、テクノロジーのパフォーマンス効率を向上させています。 これによってユーザーエクスペリエンスが向上し、ユーザー数もデータ量も増えることになります。このようなユーザーエクスペリエンスに対する正のフィードバックサイクルは、大規模AIモデルトレーニングを競争力の強化に活用することの重要性を示しています。
金融
金融では、大規模AIモデルトレーニングは不正検知のような複雑な問題の解決と前例のないレベルの効率と速度の市場トレンド分析にとって欠かせないものです。 ユーザーの行動、取引日、および金融ニュースの複雑なパターンを研究することで、不正行為や株式市場の動きをリアルタイムに予測し、専門家も顧客も区別なく危機が発生する前に是正措置を取り、リスクを取る行動を制限し、懸命な投資を行えるようにしています。
大規模モデルトレーニングの課題とは?
大規模AIモデルをトレーニングする場合、以下のような一定の課題を乗り越える必要があります。
- リソース要件: 大規模AIモデルトレーニングには莫大な計算能力とかなりのストレージ容量が必要です。 強力なハードウェアに関連して増大するコストに加えて、このような大規模なAIシステムのトレーニングと保守に必要な労力の管理に課題があります。
- データ管理と品質: データの品質と多様性を確保するには、莫大な量のデータを収集し、それをクリーニングして誤りをなくし、モデルを効率よくトレーニングするのに十分な変化を持たせ、それによって結果に偏りを生じさせるバイアスを防ぐ必要があります。 データ量が多くなるほど、このステップは困難になります。
- 人材と専門知識: このような大規模AIモデルを設計、開発、および管理できる優秀な専門家に対するニーズは高まっており、業界では人材不足が発生しています。
- 環境および倫理上の懸念: 大規模AIモデルのトレーニングに要するエネルギー消費量は、二酸化炭素排出量(これは、よりエネルギー効率の高いハードウェアを活用し、電力使用量を減らすアルゴリズムを最適化することで削減可能です)に代表される環境への影響に対する懸念を引き起こしています。
- 再現性: 大規模モデルは複雑であるため、その結果を再現するのが困難な場合があります。 科学研究で結果を検証する場合、再現性は極めて重要です。 標準化されたテスト環境を導入し、トレーニングプロセスを徹底的にドキュメント化し、モデルのアーキテクチャとパラメーターを科学コミュニティ内でオープンに共有することで、この課題を克服できる可能性があります。
適切な計画を策定すれば、これらの課題の多くを克服できることは明らかです。
まとめ
大規模AIモデルは従来のデータセット手法よりも明確に有利です。 その複雑さを乗り越えてベストプラクティスに従うのは困難かもしれませんが、AIの能力を大規模に取り入れた場合には、絶え間なく進化する競争の激しい業界の最前線に立つことができます。
GcoreはそのAIサービスとしてのインフラストラクチャモデルによって大規模AIモデルトレーニングを単純化し、PyTorch、Tensor Flow、Keras、およびPaddlePaddleなどの代表的なAIおよびMLフレームワークを統合した最高級の強力なNVIDIA L40S、H100、およびA100 GPUを提供します。 高い効率と速度のトレーニングにより、より迅速な導入とビジネスインパクトを実現できます。 Gcoreのデータ統合とモデルの並列処理は、AIトレーニングプロセスのスケーラビリティと速度をさらに強化します。 しかも使用した分だけを支払う従業課金制であるため、データセットの規模を問わずAIトレーニングのニーズに対応したコスト効率の高いソリューションとなっています。

